Recently I was working on a feature that allowed customers to exchange products for other (relevant) products to retain revenue. The question that came up was how we can find products that are relevant to propose to the customer. Traditional approaches may have involved a rule‑based system where, based on some rules, we look into the metadata of a product like the category it belongs to or the tags it has and find products that have the same metadata. This approach is very manual and error‑prone, since someone would have to keep these rules updated, e.g., when a new product is added to the catalog or when categories/tags change.
Another approach would have been to use lexical matching. Lexical matching is a set of retrieval methods that match search queries directly with items based solely on exact or near-exact keyword overlaps, without deeper semantic understanding. For example, searching for "car" matches items explicitly containing the term "car." These methods are known to suffer from a vocabulary gap problem. The vocabulary problem arises because users often choose search terms different from those used in item descriptions, causing a "vocabulary gap." Thus, even if relevant products exist, they may not be retrieved due to differences in vocabulary between queries and item descriptions.
Another approach would have been to use an LLM, pass the product catalog and ask the LLM what it believes are the more similar products. The main problems with this approach are 1) limited context window 2) slow latency/response time.
We decided that none of these approaches fit our need and started looking for alternatives.
One of those was using embeddings. Embeddings are just high‑dimensional numeric vectors that capture the meaning of items (words, sentences, images, etc.) so that similar things end up close together.
In the following example, phones are close to each other while the shoes are quite far.
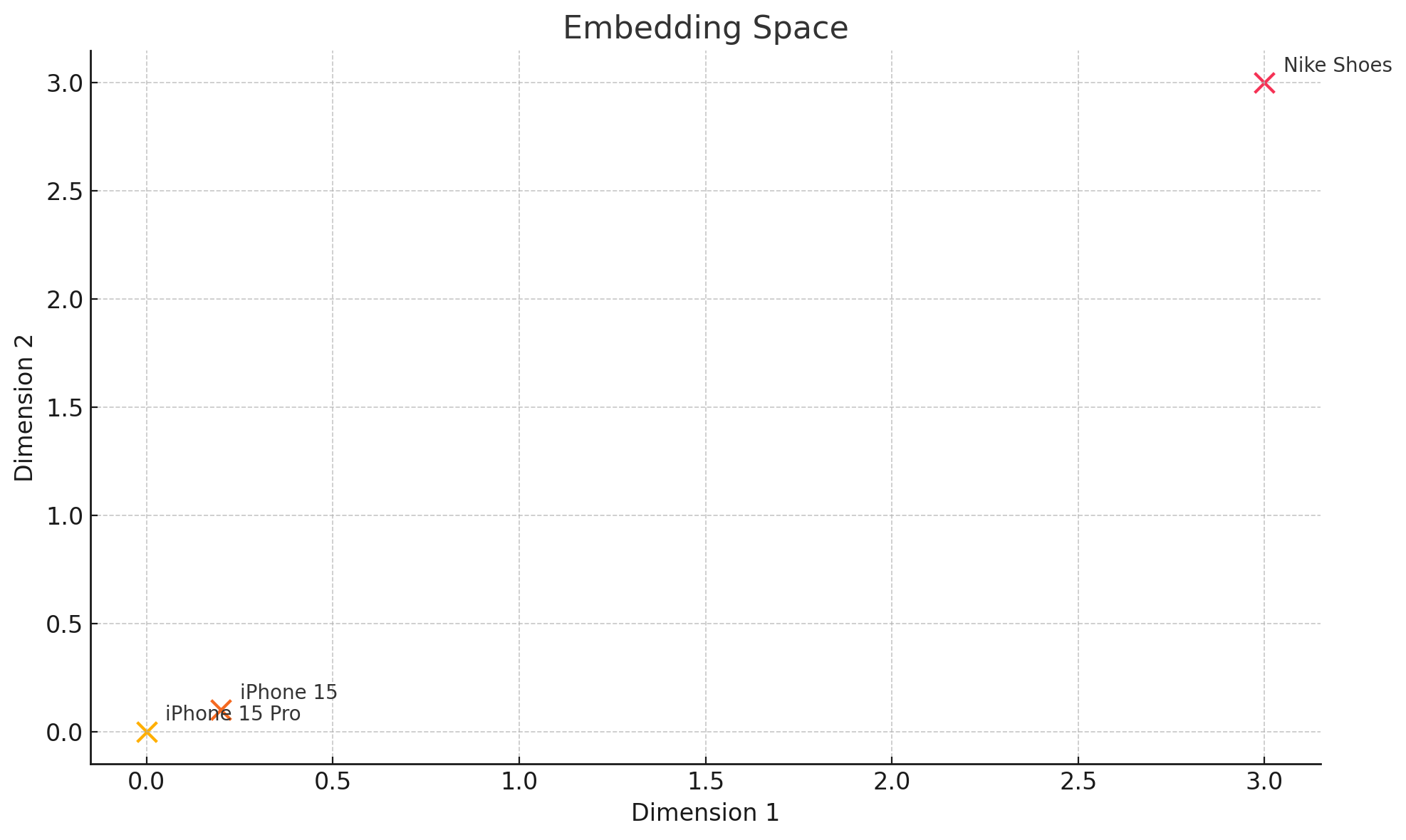
Using OpenAI’s text‑embedding‑3‑small, we started generating embeddings for products using not just tags and categories but also the name, description, and other information. Many believe that to use embeddings, someone needs a dedicated vector database, but you can go very far by simply using the pgvector extension of Postgres, enabled by default on AWS, so we took advantage of that.
scope :similar_to, ->(product, limit: MAX_SIMILAR_PRODUCTS) {
return none unless product.embedding
joins(:product_embedding)
.where.not(id: product.id) # Exclude the product itself
.where(shop_id: product.shop_id) # Only products from the same shop
.order(Arel.sql("product_embeddings.embedding <=> '#{product.embedding}'::vector"))
.limit(limit)
}This ActiveRecord scope finds products similar to a given product based on embedding vectors.
- Returns an empty relation (none) if the given product has no embedding.
- Joins with the product_embedding table/model.
- Excludes the original product from results.
- Limits products to the same shop_id.
- Orders products by vector similarity (
<=>) compared to the provided product's embedding vector. - Limits the number of results to the given limit.
- The
<=>operator is used by PostgreSQL (pgvector extension) to calculate vector similarity.
Two tower embeddings
The previous approach was good enough for our use case, but reading more about embeddings I stumbled upon a paper from Etsy where they introduce a two tower approach where thay take into consideration not just the embedding of the product but also the User + UserQuery embedding, and apply a weighted function to boost results that are more likely to be suitable for the given user.
Practically we can implement a Query‑User Encoder that is just a function that takes the original product (the one the customer wants to exchange) plus any user context (location, recent clicks, preferences, etc.), embeds each piece and then fuses them into one fixed‑length vector. That vector lives in the same space as our product embeddings, so we can dot‑score query ↔ product.
async function recommendExchanges(
user: User,
productX: Product,
catalog: Product[],
catalogEmbs: number[][],
k = 6
): Promise<Product[]> {
const [uVec, xVec] = await Promise.all([
embedUser(user),
embedProduct(productX)
]);
const ppCands = await vectorIndex.query({ vector: xVec, topK: 100 });
const α = 0.7, β = 0.3;
const scored = await Promise.all(
ppCands.map(async ({ id, score: simPP }) => {
const p = catalog[id];
const simUP = await scoreUserProduct(user, productX, p);
return { p, score: α*simPP + β*simUP };
})
);
return scored
.sort((a,b) => b.score - a.score)
.slice(0, k)
.map(x => x.p);
}
The embedUser needs to be an embedder model that is fine tune based on historical swaps.
OpenAI doesn't offer fine-tuning on embedding models but we can come close to that architecture by
doing fine-tuning on a generic GPT and applying the following:
- Embeddings: every product and user becomes a 1,536‑dim vector via
text-embedding-ada-002. - Retrieval: fast ANN gives you the top ~20 “similar to X”
- Fine-tuned reranker: a small GPT‑style model (fine‑tuned on past user↔product signals) reads the user+product text and outputs a 0–1 match score (= simUP).
- Fuse: combine simPP and simUP with weights α/β to balance pure similarity vs. user fit.
async function recommendExchanges(
user: User,
productX: Product,
catalog: Product[],
k = 5
) {
const [uVec, xVec] = await Promise.all([
embedUser(user),
embedProduct(productX)
]);
// A) rough PP retrieval:
const candidates = await vectorIndex.query({
vector: xVec,
topK: 20
}); // returns { id, score: simPP }
// B) rerank with a fine‑tuned GPT model that scores UX affinity
const reranked = await Promise.all(
candidates.map(async ({ id, score: simPP }) => {
const p = catalog.find((_, i) => i === id)!;
const prompt = `
User:
Location: ${user.location}
Gender: ${user.gender}
Age: ${user.age}
Product:
Name: ${p.name}
Desc: ${p.description}
Tags: ${p.tags.join(", ")}
Cats: ${p.categories.join(", ")}
On a scale 0–1, how good a match is this exchange?`;
const resp = await openai.chat.completions.create({
model: "our-fine-tuned-gpt",
messages: [{ role: "user", content: prompt }],
temperature: 0
});
const simUP = parseFloat(resp.choices[0].message.content);
const α = 0.7, β = 0.3;
return { p, score: α * simPP + β * simUP };
})
);
return reranked
.sort((a, b) => b.score - a.score)
.slice(0, k)
.map(x => x.p);
}