This is one of those funny stories about a bug you want to remember to tell your grandkids before bed (omg, what a terrible grandpa I'm going to be). Anyway, a few days ago our DMS replication started failing. Redshift was rejecting rows. The pipeline was choking. Nothing had changed in the pipeline, how on earth was that happening?
The culprit? Moldova. A land between Romania and Ukraine that's essentially the European version of a hidden track on a CD, a country in "intense flirting" stage with the European Union while the ex-boyfriend (Vladimir Putin) fights to win her back. So the problem was Moldova. More specifically: Moldova, Republic of, the official Shopify name for the country, complete with a comma sitting right in the middle of it.
Here's what was happening. We were consuming through a background job the Delivery Countries of merchants from the Shopify API, and through a DMS we were replicating some data to another database for analytics purposes.
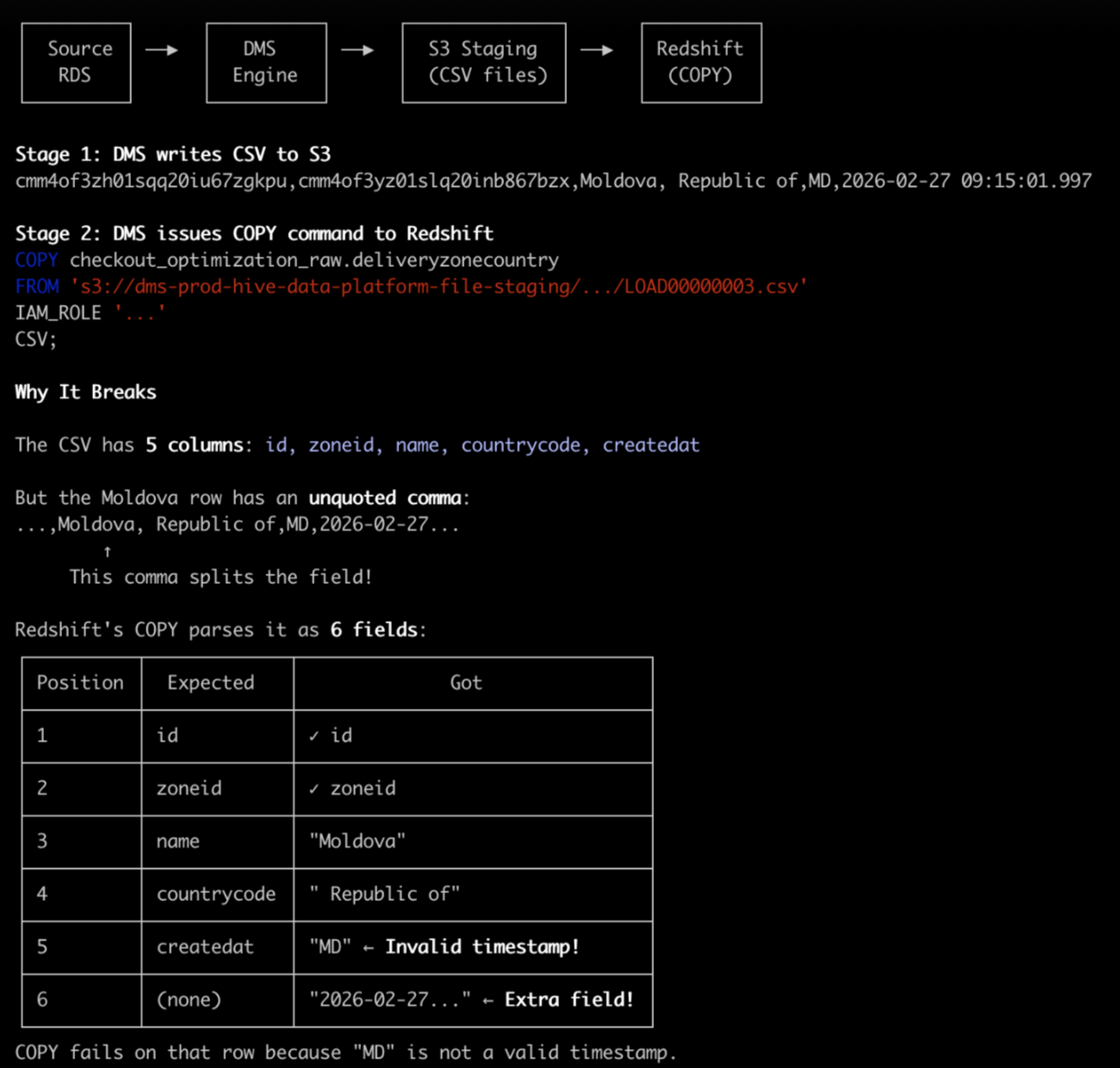
DMS replicates our RDS tables to Redshift by writing CSV files to S3 and then issuing a COPY command. The problem is that DMS wasn't quoting field values. So a row that should look like:
was being written as:
Redshift sees 6 columns instead of 5. MD ends up in the createdAt field. Redshift screams. Pipeline dies.
Thank God for Claude, these days it can help tremendously with debugging by chewing through tons of logs.
The wrong fix
The obvious move is to rename the record in the source database. Takes 3 seconds, pipeline recovers, everyone goes home happy.
Except the sync job runs on a schedule, and Shopify will happily send Moldova, Republic of right back on the next run, restoring the chaos. You've fixed the symptom, not the cause, and you've introduced a silent landmine that resets itself.
The "kinda ok" solution
The kinda ok solution is to sanitize the name at write time in the sync job itself, before the data ever touches the database. Replace , with - at the boundary:
Moldova, Republic of becomes Moldova - Republic of. Perfectly readable, CSV-safe, and idempotent, every sync will write the same clean value regardless of what Shopify sends. You can run it a thousand times and the result is the same.
The real real fix
There are two other ways to fix the issue. The first is to change the CSV delimiter. DMS lets you configure the delimiter on the S3 target endpoint via extra connection attributes. Swap the comma for a pipe or a tab (something that will never appear in your data) and embedded commas stop being a problem entirely. At the same time, it's hard to know which special characters may appear in the data.
The second, more thorough option is to stop using CSV altogether and switch to Parquet. Parquet is columnar and schema-aware. There's no delimiter character, so embedded commas, newlines, quotes — all of it just works. Redshift's COPY command supports Parquet natively and actually performs better loading it than CSV.
Both of these fix the transport layer, which is the right abstraction for a transport problem. But they don't change what's in RDS. If anything reads from the database directly (another job, a report, an API), it still gets Moldova, Republic of. The sync-job sanitization fixes the data, not just the delivery format.
The best version is both: switch DMS to Parquet so the pipeline is resilient to whatever comes through, and still sanitize at the sync boundary so the stored data is clean. Each layer handles what it owns.
Sanitize at the boundary
There's a broader pattern here. External data sources (Shopify, third-party APIs, user input) will always find the exact edge case your infrastructure doesn't handle. They don't do it maliciously. They just don't know (or care) about your CSV pipeline, your column count, your COPY command. They're just sending you the data they have.
The temptation is to fix these things downstream. Patch the COPY command config, add a cleanup step in the warehouse, write a one-time migration script. These all work until the next Moldova shows up, and there's always a next Moldova.
The right place to deal with external data is at the boundary, the moment you first ingest it. Validate it, normalize it, sanitize it there, not two services later when the damage is already done and the error message is "invalid column count on row 4,721."
It’s a strange world when a sovereign nation’s formal title is the main character in your error logs. Moldova, if you’re reading this, I’ll support your EU bid, no matter how you spell your name.