I was reading about different techniques on optimizing the answers of RAG and I stumbled upon HyDE (Hypothetical Document Embeddings) so decided to give it a try in a PoC.
One of the issues in RAG retrieval is that queries and answers usually have very different shape, a query is a question while the knowledge base is full of statements. For example, "How do I rotate an expired API key?" and "Key regeneration is performed from the project settings panel" are about the same thing but they do not have very little in common as structure. Even if we use an embeddings model the answer and question are very far in the vector space, practically because there are different kinds of text.
One is short, interrogative, and written in the user's vocabulary. The other is long, declarative, and written in the documentation's vocabulary. We are asking the embedding to bridge a gap it was never trained to care about. This is the core observation behind HyDE (Gao et al., 2022).
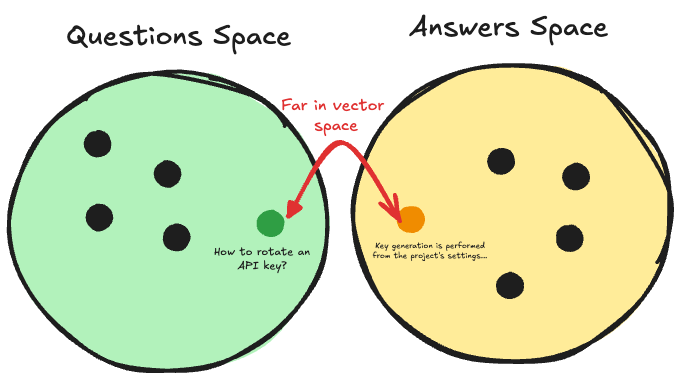
The fix to this problem is to stop comparing questions to answers, and start comparing answers to answers, or questions to questions.
Fake the answer at query time
HyDE (Hypothetical Document Embeddings) proposes the following: before retrieving the answer, ask an LLM to hallucinate an answer to the query, then embeds that answer and search with it for similar answers in the knowledge base.
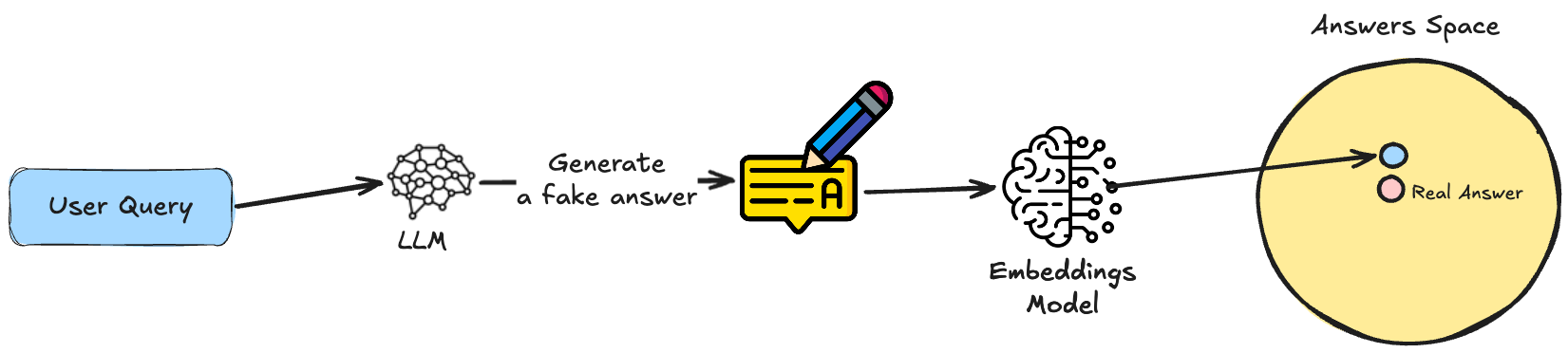
The hypothetical document for that query might read "To rotate an API key, open the project settings, regenerate the key, and update your environment variables. The old key stops working immediately."
The hypothetical answer can be wrong and HyDE still works, because you never show its content to anyone. It is used only as a way to find a better neighborhood, then retrieve real documents from there. The cost is that HyDE adds an LLM generation and embedding call to every single query, aka extra latency and token cost on every query.
Reverse HyDE: fake the questions at index time
In reverse HyDE instead of turning the query into answer-shaped text at search time, it turns each document into question-shaped text when you index it. For every chunk, you ask an LLM to write the questions that chunk could answer, embed those, and store them pointing back at the chunk/document.

The regeneration page now has index entries for "how do I rotate an API key?", "what happens to my old key after I regenerate it?", and "where do I change my API credentials?".
When the real query arrives, it matches against question-shaped text written in the user's own register. There is no generation at query time. You embed the incoming query and search as usual.
The actual difference is when
The difference in the two ways is when the LLM does the work.
- HyDE spends compute per query. Every search pays for one generation.
- Reverse HyDE spends compute per document, once, at ingestion. Every search after that is cheap.
If the use-case is something where latency cant be afforded, then obviously Reverse HyDE is more suitable. On the other hand if knowledge base is changing too often, which requires re-indexing, HyDE is more suitable (given that latency is not an issue).

My PoC
The diagrams above are drawn by hand. To check that the effect is real and not just a nice story, I did a small PoC using a free embeddings model (all-MiniLM-L6-v2 via transformers.js).
Search the raw query against the corpus and the right page lands at rank 6, buried under documents that merely share surface words like "rotation policy" and "token expired" but do not answer the question.

The asymmetry is easy to see. Compare the query against its own answer and against other questions about API keys, and 4 of 5 of those questions sit closer to the query than the answer does, even though none of them is the answer. That's obviously expected.

Switch to HyDE, embedding a fake answer instead of the query, and the right page climbs from rank 6 to rank 3. It does not reach the top, two documents that genuinely discuss key rotation and expiry still rank above it. The fake answer clears out some generic noise, but it in this case it cannot beat documents that really are about the same thing.

Reverse HyDE takes it to rank 1 outright. The user's almost-exact phrasing was generated and indexed ahead of time, so the query matches question-to-question.

This is ofcourse not a benchmark, my PoC had a corpus that is tiny and the numbers can be noisy, but it demonstrates that they technique works and is valid tool in the toolbox of everyone trying to optimize a RAG system.