A few days ago I was looking at our monitoring dashboard when I noticed something odd. Our storefront API, which normally responds in under 10ms, was spiking to 350ms , once every 24 hours, like clockwork.
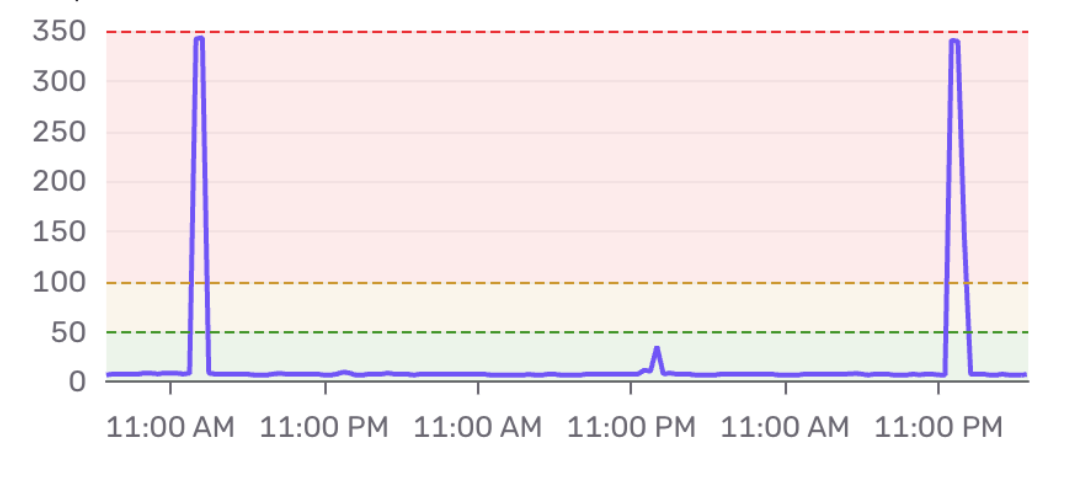
The shape of the spike is the tell. It's not a gradual degradation. It's a sharp vertical jump, a brief plateau, and then an instant recovery back to baseline. If you've seen this pattern before, you probably already know what's going on.
This is a cache stampede.
What is a cache stampede?
A cache stampede (also called a thundering herd) happens when a cached value expires and multiple concurrent requests all discover the cache miss at the same time. Instead of one request fetching from the database and repopulating the cache, every request does.
Here's the sequence:
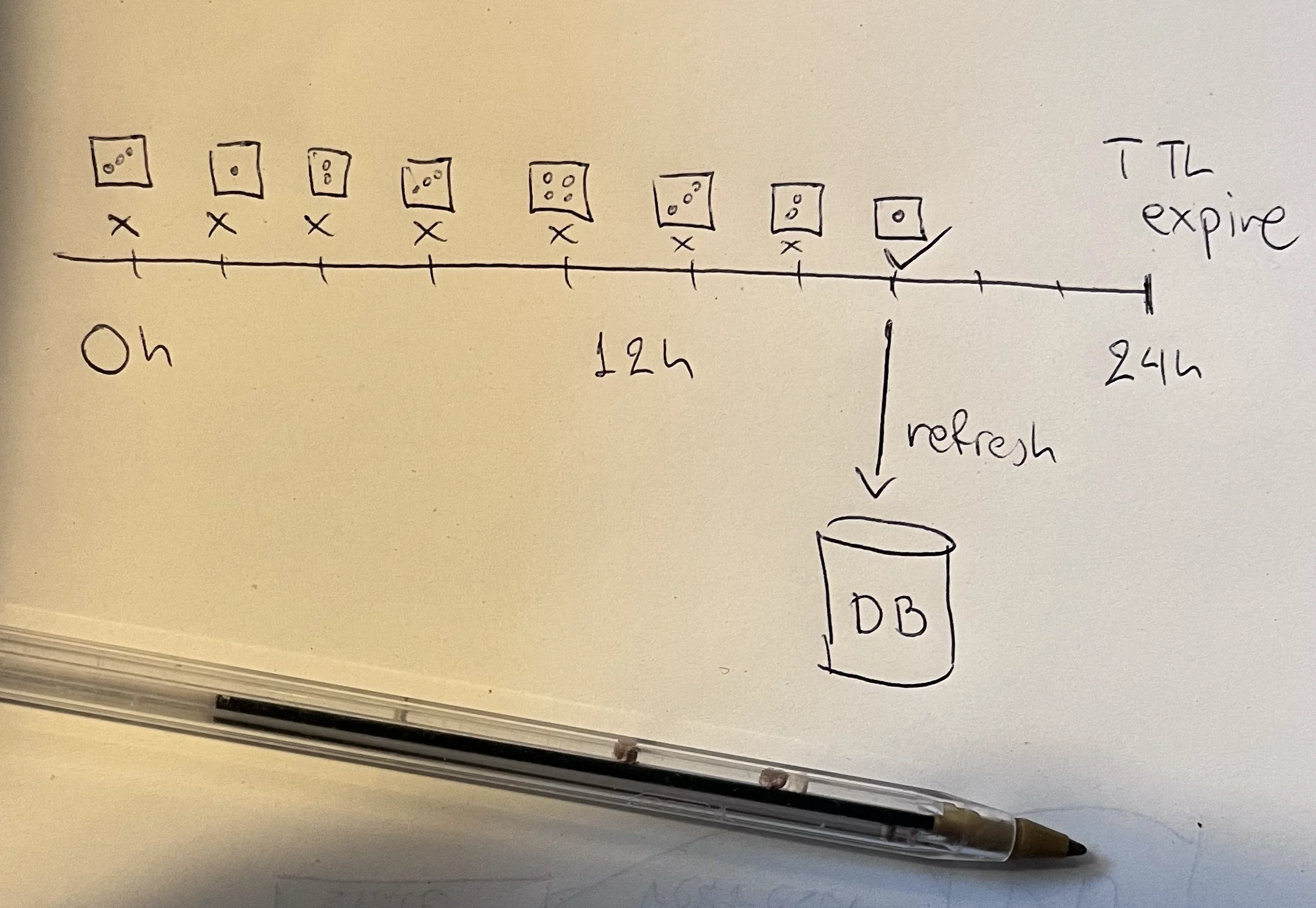
- A cache key has a 24-hour TTL
- At hour 24, the key expires
- Hundreds of concurrent requests arrive and all check the cache
- They all see a miss
- They all hit the database simultaneously
- Response times spike
- One of them writes the result back to the cache
- All subsequent requests are fast again
The problem scales with traffic. At 10 requests per second, you get 10 simultaneous database queries. At 1,000 requests per second, you get 1,000. The database gets hit with a sudden burst it wasn't designed to handle, and response times spike until the cache is repopulated.
Why a longer TTL doesn't fix it
My first instinct was simple: just extend the TTL. If the cache expires every 24 hours and that causes a stampede, why not set it to a year?
That reduces the frequency of the stampede from daily to yearly, but it doesn't eliminate it. When that year-long TTL eventually expires you get the same spike. You've traded a daily papercut for a yearly one, but the underlying problem is unchanged.
Mutex lock (single-flight)
The most direct fix is to ensure that only one request fetches from the database on a cache miss, while all other concurrent requests wait for the result. This is sometimes called single-flight after Go's standard library implementation, though the pattern predates it. The Redis documentation covers this as the lock-based stampede prevention pattern.
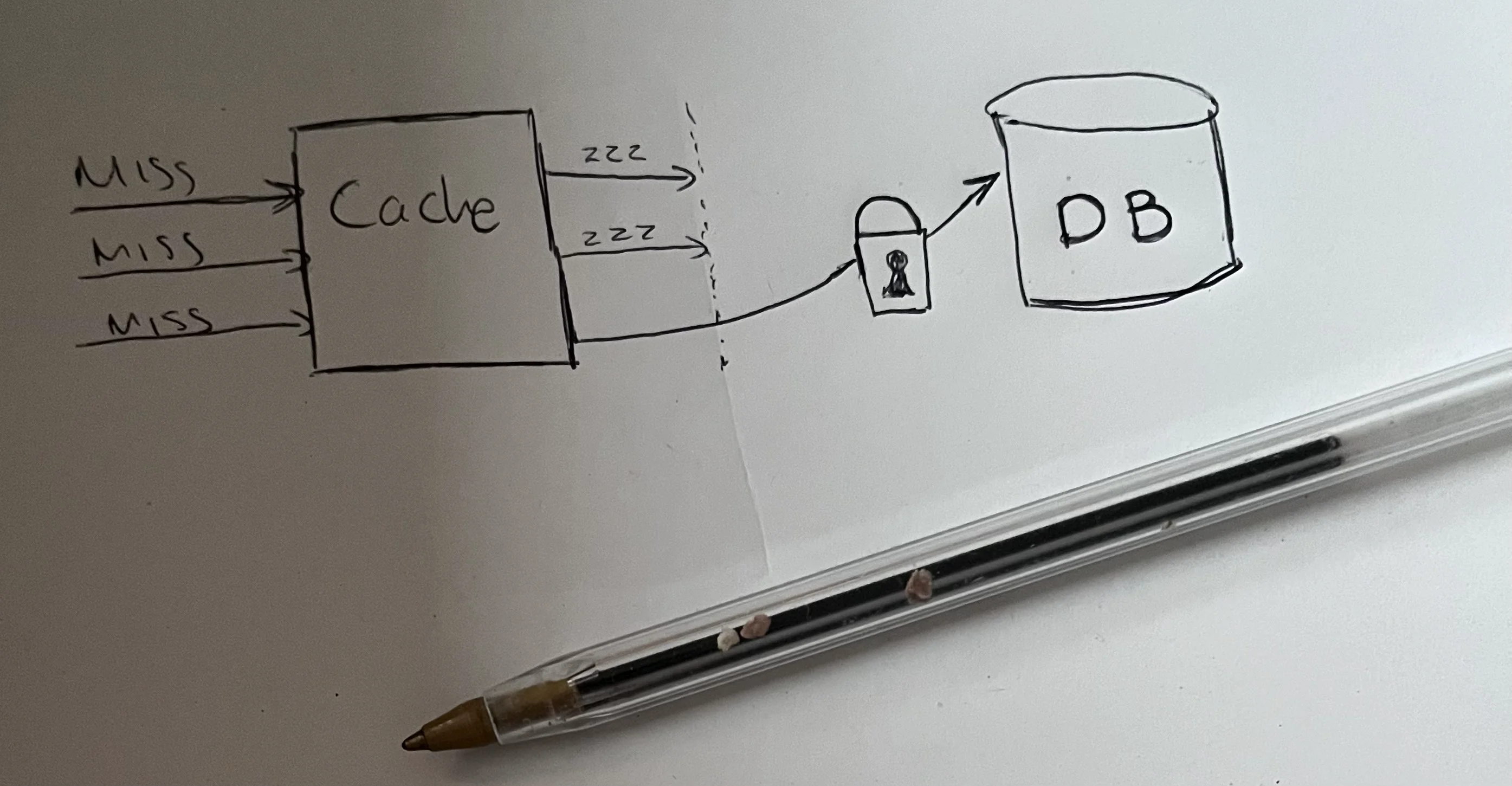
Pros:
- Eliminates the stampede completely , only one request hits the database
- Handles cold cache misses gracefully
Cons:
- Adds latency for waiting requests (they poll until the cache is repopulated)
- Introduces complexity: what if the lock holder crashes? You need a lock TTL as a safety net
- The recursive retry can stack up if the fetch is slow
Solution 2: Stale-while-revalidate
Instead of making requests wait, serve the stale cached value while one request refreshes it in the background.
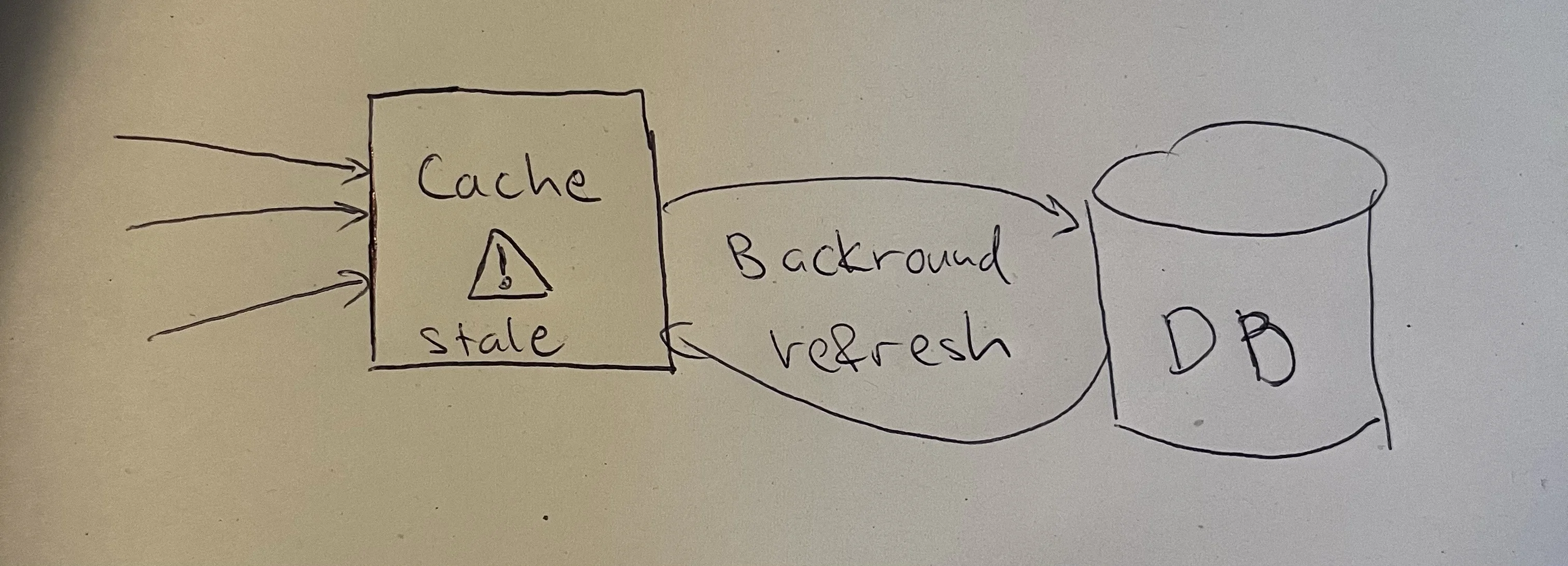
This is the same concept as the HTTP Cache-Control: stale-while-revalidate header, applied at the application cache level.
Pros:
- Zero additional latency , every request gets a response immediately
- Simple mental model: always serve what you have, refresh in the background
Cons:
- Brief window where stale data is served (usually acceptable)
- Doesn't help on a cold cache miss (first request still hits DB)
- You need to store metadata alongside the cached value to track freshness
Probabilistic early expiration
This approach, sometimes called XFetch after the original paper by Vattani, Chierichetti, and Lowenstein (VLDB 2015), adds randomness to when each request decides the cache is "expired." Instead of all requests seeing the expiration at the exact same moment, some requests probabilistically trigger a refresh before the TTL expires.
The beta parameter controls how aggressively requests refresh early. Higher values mean earlier refresh, which reduces stampede risk but increases unnecessary database queries. Cloudflare published their production implementation of this pattern in December 2024 for their Privacy Pass Issuer service.
Pros:
- Elegant , no locks, no background jobs, no extra infrastructure
- Statistically prevents stampedes without coordination between requests
- Proven mathematically optimal , the original paper by Vattani, Chierichetti, and Lowenstein (2015) shows the exponential distribution minimizes both stampedes and unnecessary recomputations
Cons:
- Some requests still hit the database unnecessarily (probabilistic by design)
- More complex to reason about and tune than a simple lock
- Doesn't help on a cold cache miss or for rarely accessed keys (not enough "dice rolls" before expiry)
Background refresh (proactive warming)
Instead of waiting for a cache miss, a background worker refreshes the cache before it expires. Netflix operates this pattern at massive scale with EVCache, warming petabytes of cache data proactively.
Pros:
- Requests never see a cache miss under normal operation
- Shifts database load from user-facing requests to a background job
- Zero latency impact on the serving path
Cons:
- Requires a worker/cron infrastructure
- Cache can still go cold on deploy or Redis restart
- You need to know which keys to refresh in advance (doesn't work well for user-specific caches)
TTL jitter
The simplest possible fix. When setting a cache key, add a random offset to the TTL so that keys don't all expire at the same moment. AWS recommends this as a baseline strategy, combined with exponential backoff and jitter for retries.
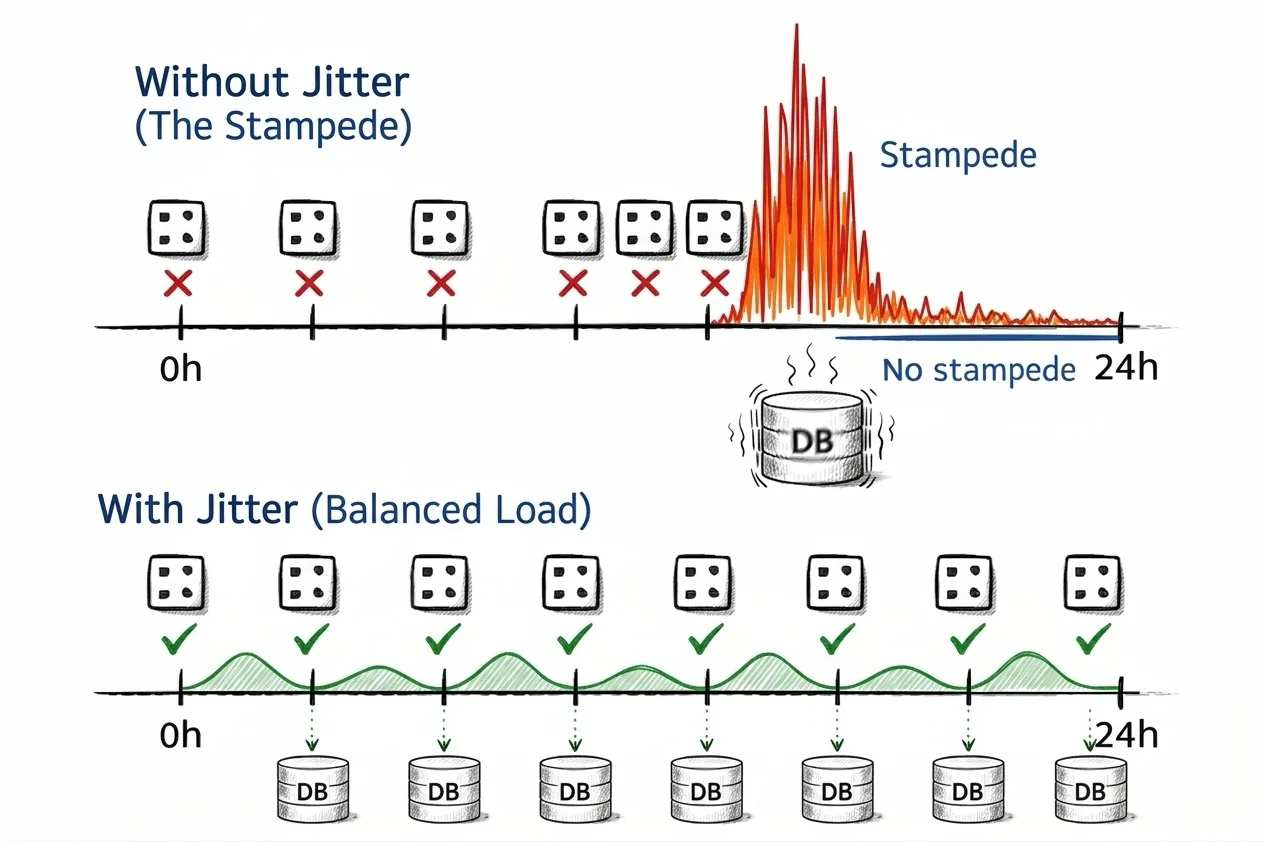
This is one line of code and it prevents the scenario where a deployment warms thousands of keys with identical TTLs, causing them all to expire in the same second.
Pros:
- Trivial to implement , one line of code
- Prevents mass expiration of different keys at the same time
- Best used as a baseline defense combined with other solutions
Cons:
- Does nothing for a single hot key (there's only one TTL to randomize)
- Doesn't prevent stampedes, only spreads them out over time
- No help on cold cache misses
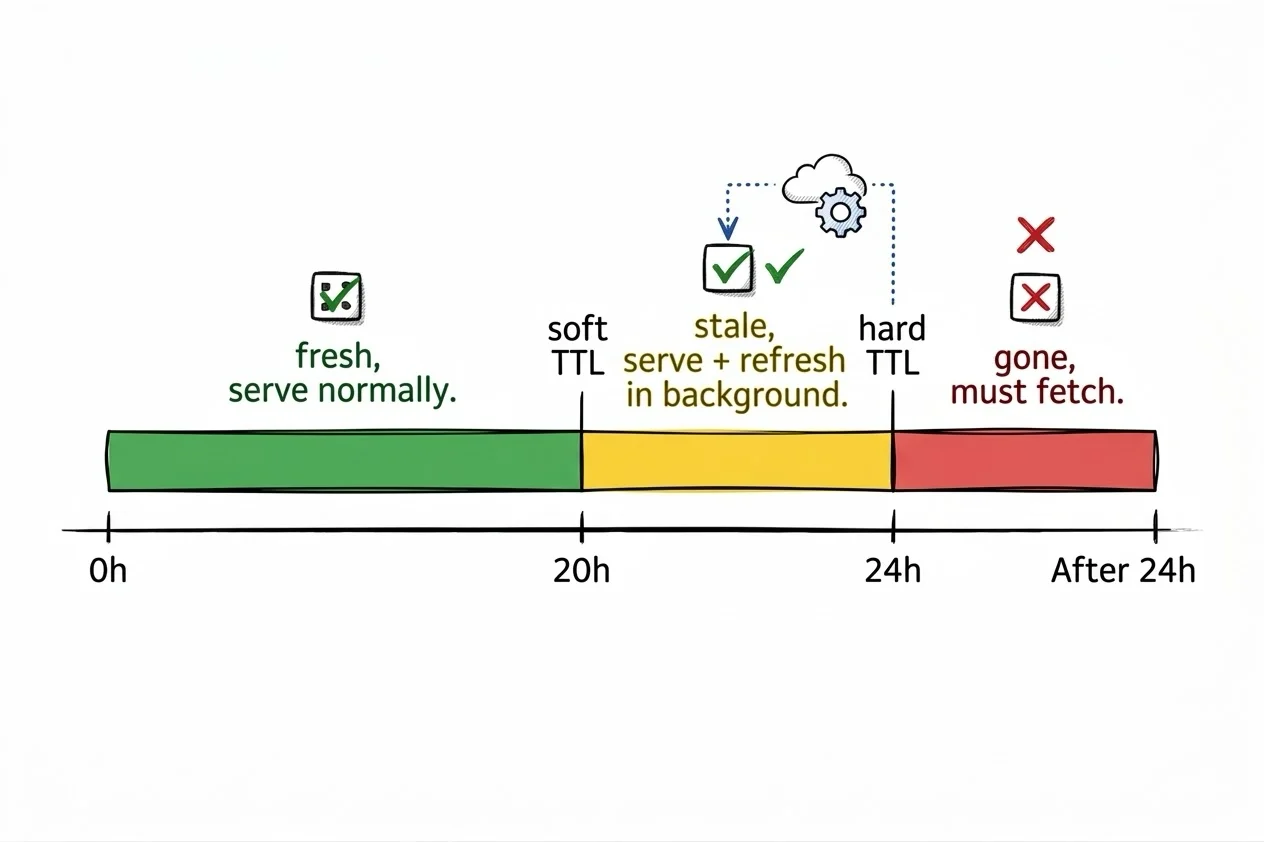
Two-key / soft-hard TTL
Store each cached value with two expiration times: a short "soft" TTL and a longer "hard" TTL. The soft TTL controls when a refresh should happen. The hard TTL controls when the value is truly gone.
The difference from stale-while-revalidate is that the hard TTL acts as a safety net. If the background refresh fails repeatedly, the stale value is still served until the hard TTL expires. This gives you a built-in grace period.
Pros:
- More resilient than plain stale-while-revalidate , the hard TTL is a safety net
- Zero latency impact during the stale window
- If background refresh fails, stale data is still served until the hard TTL expires
Cons:
- Doubles your TTL management complexity (two expiries to reason about)
- Doesn't help on a cold cache miss
- The soft/hard gap needs careful tuning: too small and you lose the safety net, too large and you serve stale data for too long
Request collapsing at the CDN/proxy layer
If your cache sits behind a reverse proxy or CDN , Nginx, Varnish, Fastly, Cloudflare , you can let the infrastructure handle it. When multiple clients request the same uncached resource simultaneously, the proxy holds all but the first request, sends one to your origin, and fans the response out to all waiting clients.
Pros:
- Handles stampedes before they reach your application , zero code changes
- Built into most CDN/proxy infrastructure
- Handles cold cache misses gracefully
Cons:
- Only works for HTTP-level caching (not arbitrary Redis keys or application-level caches)
- Held requests add latency equal to the origin response time
- Doesn't help with internal service-to-service caching
Which one should you pick?
It depends on your constraints:
| Solution | Stampede prevention | Latency impact | Complexity | Cold cache handling |
|---|---|---|---|---|
| Mutex lock | Complete | Adds wait time | Medium | Yes |
| Stale-while-revalidate | Mostly | None | Medium | No |
| Probabilistic early expiry | Statistical | None | Medium | No |
| Background refresh | Complete | None | Medium | No |
| TTL jitter | Mass expiration only | None | Low | No |
| Two-key / soft-hard TTL | Mostly | None | Medium | No |
| CDN/proxy collapsing | Complete | Adds wait time | Low | Yes |
For the API that triggered this investigation, the data changes rarely and is read thousands of times per second. A combination of explicit invalidation on writes plus a mutex lock for cache misses covers all cases: normal operation sees zero stampedes, admin writes invalidate cleanly, and cold starts after a deploy are handled gracefully by the lock.
If you're dealing with higher write rates or can tolerate briefly stale data, stale-while-revalidate is hard to beat for its simplicity and zero-latency guarantee.
The key insight is that TTL-based expiration is the root cause, not the solution. Any fix that relies solely on making the TTL longer is just reducing the frequency of the problem without addressing it. The real fix is controlling what happens when a cache miss occurs.