As I learn more about agents and building applications and workflows with them, I wanted to document my learnings since writing them down helps me understand things deeper. This is the first article of a series on agentic patterns.
We have spent two decades learning how to build distributed systems that stay up when parts of them fall over. Retries, timeouts, bulkheads, backpressure, circuit breakers. Agents are "distributed systems" too. The model is a flaky dependency. The tools are flaky dependencies. The orchestrator in the middle is the service that glues them together. You would not call an unreliable HTTP API in a tight loop without guardrails, but that is what the default agent loop does every time it hands control back to the model.
The pattern, briefly
A circuit breaker sits between a caller and a dependency and tracks failure. It has three states. Closed: calls pass through and failures are counted. Open: calls fail immediately without hitting the dependency. Half-open: after a cooldown, one or two probe calls decide whether to close the breaker again or keep it open.
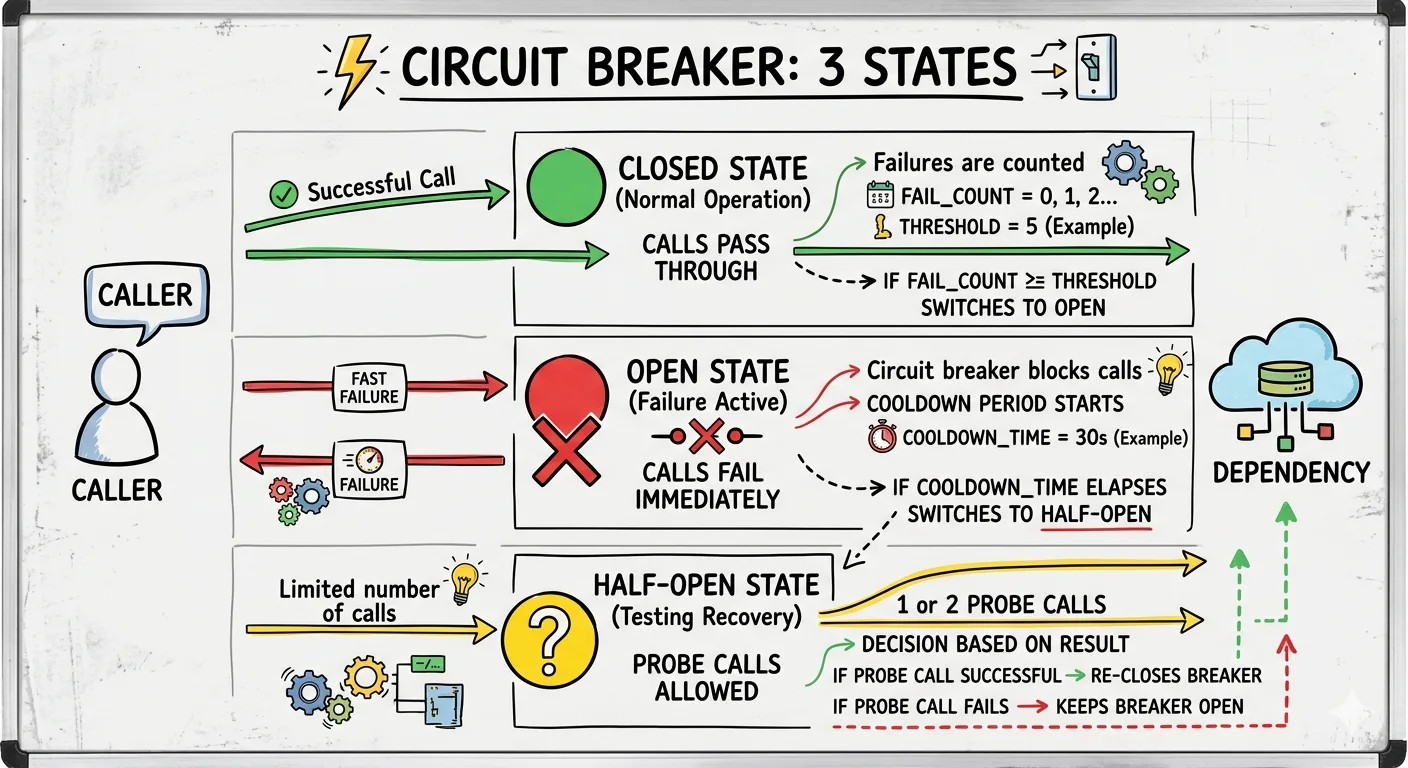
The point of the breaker is not to avoid failure. The point is to avoid making failure worse. When a dependency is struggling, piling more requests onto it delays recovery. The breaker trades a short burst of fast failures for a system that actually heals.
Why error counts stop working
Classic breakers trip on error rates. That assumes two things. First, that calls fail loudly. Second, that the failure rate is a good proxy for harm.
Neither is true for agents.
Agents fail quietly. A tool returns {"status": "ok", "results": []} and the model, lacking a better idea, calls it again with slightly different arguments. Nothing is erroring. The loop continues until a token budget somewhere explodes.
Agents also fail expensively without failing at all. Two minutes of successful tool calls that make no progress toward the goal is not something an error counter can see. The model is confident, the tools are returning 200s, and the only signal that something is wrong is that the same conversation keeps going in circles.
And agents fail in ways that are not about the outside world. A tool can be perfectly healthy while the model repeatedly asks it the wrong question. That is not a dependency failure. It is a reasoning failure.
The fix is to stop thinking of "the breaker" as a single thing and start thinking of it as three orthogonal ones.
Three layers
Transport. The familiar one. Counts 5xx responses, timeouts, and refused connections per tool. Trips when a specific tool is unhealthy. Recovers with a half-open probe. Nothing here is agent-specific, and that is the point: keep the layer that already works, and do not overload it with new responsibilities.
Semantic. The one that catches the quiet failures. It looks at the shape of the last N tool calls, not their success. Same tool, same argument fingerprint, same empty result, three times inside a short window? That is a loop. The transport breaker will never catch it because nothing erred. The semantic breaker trips on repetition and asks the model, explicitly, to do something different.
Budget. The one that guarantees a bounded blast radius. Tokens spent, tool calls made, wall-clock elapsed, cost accumulated. When any of those cross a threshold, the breaker opens regardless of whether anything is wrong. It is not a reliability mechanism. It is a safety mechanism.
The three layers compose. Transport handles the outside world. Semantic handles the model's self-inflicted wounds. Budget handles the case where you were wrong about the other two.
Wrapping a LangChain tool
The smallest useful version of this is a wrapper around a LangChain tool. Everything below is TypeScript, using @langchain/core.
That is the familiar piece. Now the semantic layer, which sees a window of calls instead of a single one.
And the budget layer, which only cares about totals.
Stitching them together into a LangChain tool is where the pattern pays off. The three breakers live outside the model, the tool wrapper enforces them, and the model sees a normal tool interface. BreakerTripped is a small Error subclass that carries which layer fired. hash and estimateTokens are whatever you already use (a stable stringify and your tokenizer of choice).
The BreakerTripped error is deliberate. When it reaches the agent's message loop you do not want to retry it. You want to turn it into a terminal observation that the model can reason about: the X tool has been stopped because you called it the same way repeatedly with the same result. Choose a different approach or stop. That message, injected as a tool result rather than thrown as an exception, is usually enough to break the loop without killing the run.
A few tuning notes
It is tempting to pick round numbers: three failures, five repeats, ten thousand tokens. Fine for a start, bad as a resting state. Tune to the shape of real traffic, not intuition.
For the transport breaker, keep the threshold low enough to protect downstream but high enough to tolerate blips. Three is usually fine. Five can feel slow.
For the semantic breaker, window size matters more than repeat count. Too small misses loops across turns, too large flags normal retries. Start with a window of ten and repeat count of three, then adjust.
For the budget breaker, set limits you can defend in a cost review. A run over one euro should have a reason. Charging by estimated tokens before the call is enough to stop runaway spend, but if you want accurate accounting, settle the charge with the model's reported usage after the response comes back.
The circuit breaker is not a clever pattern. It is an old one, and that is the point. When the novel-looking failures in your agent system start resolving into familiar shapes (unhealthy dependencies, runaway costs, pathological loops) you stop inventing and start reusing. The model is the new thing. Everything around it is plumbing we have built before.