In the previous post I wrote about circuit breakers for agents: how to stop a model that is looping, burning tokens, or hammering a flaky tool. Circuit breakers catch the agent that is failing. This post is about the agent that is succeeding, at the wrong thing.
A circuit breaker assumes a wrong action is one you can stop in flight. Most agent damage is not in flight. It is one well-formed call to a tool that had been given more authority than the task ever required.
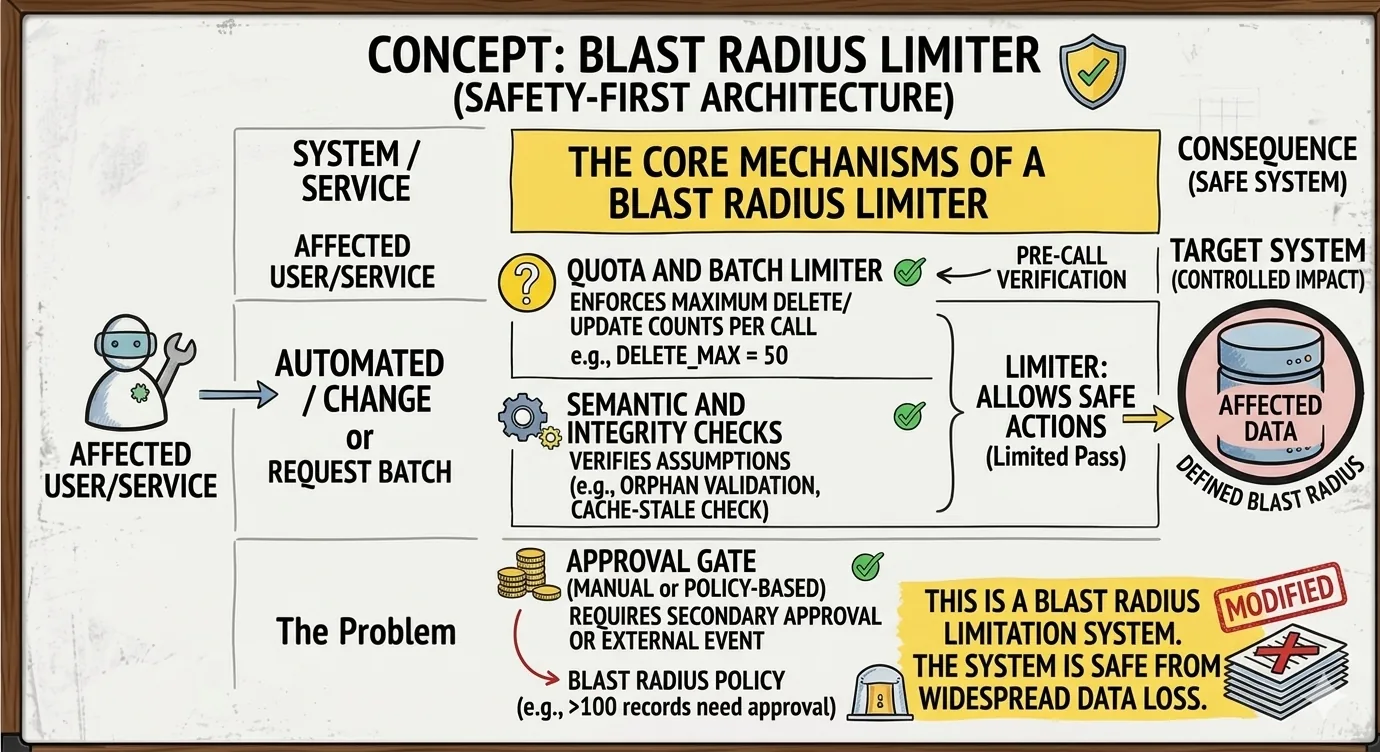
The pattern that addresses this is the Blast Radius Limiter. Where the breaker is reactive (it counts failures and opens), the limiter is structural. It decides, before the run starts, what the worst-case outcome of the run can be. The model can be wrong, the tools can be wrong, the prompt can be injected. The blast still has to fit inside the box.
Five containment layers
Blast radius is an architectural property. You do not add it after an incident. You design it in, in layers.
I will show the layers as TypeScript glue around a tool. The previous post wrapped a LangChain tool with a circuit breaker, so I will keep the same shape and the two patterns compose.
Layer 1: identity scoping. An agent run is not the agent's identity. It is a principal made up of the human delegating, the agent template, the specific run, and the task at hand. Every tool call carries that principal forward.
Layer 2: short-lived, audience-bound tokens. The agent does not hold the user's credentials. For each tool call, an identity gateway mints a token scoped to the specific MCP server or API, valid for a short window, with the principal embedded as claims.
The act claim and the resource indicator are not academic. They are what lets you revoke this run's authority without revoking the user's, and what lets you answer "who really did the delete" when it shows up in an audit trail.
Layer 3: data-layer rate limits. RPS limits are not enough. The right limit is at the data shape: rows affected per minute, bytes returned, tables touched. This sits in front of the database, not in the agent.
A summarisation agent reading fifty rows per minute is fine. The same agent suddenly writing ten thousand rows is not, and the limiter catches it before commit, not after.
Layer 4: ephemeral execution. Generated code, shell-touching tools, anything that interacts with the filesystem runs in a sandbox that lives for the duration of the run and is destroyed afterwards. Across runs, no shared state. Across tenants, no shared anything. This is the layer that makes "kill the agent" actually mean something: you tear down the sandbox and the work in flight goes with it.
Layer 5: tool invocation governance. Every high-impact tool call is checked against a policy before it runs. Not in the prompt. In code, deterministic, evaluated on principal, tool, arguments, and current state.
The needs-human branch is the part most teams skip because it requires a UX.
A guarded tool wrapper composes the layers in the same shape as the breaker from the previous post.
Five layers, none of them clever, all of them load-bearing.
The MCP tension
MCP is the protocol that made all of this urgent and is also the thing that makes it hardest. The default deployment pattern for an MCP server is one server, one token, every tool the server exposes. That is the productivity story. It is also the largest blast-radius footgun in the agent ecosystem.
A db:* scope on a Postgres MCP server gives the agent everything: SELECT, INSERT, UPDATE, DELETE, schema introspection. The June 2025 MCP spec update introduced OAuth 2.1 with PKCE, capability-level scoping, and resource-indicator tokens specifically to fix this. Most servers in the wild still do not implement it. If you are building or adopting an MCP server today, this is the question to ask first: what is the smallest scope this token can carry, and how short is its lifetime? "Files-read on this directory for sixty seconds" is a sentence the protocol now supports. Use it.
Where this leaves us
The breaker stops the agent that is going wrong. The limiter bounds the agent that is going wrong correctly. Together they cover the failure modes of a single agent.
Production systems rarely have a single agent. They have planners delegating to specialists, specialists calling other specialists, and orchestrators trying to keep the whole shape coherent. The next post in the series is about that: orchestrator versus choreography, when to reach for each, and why the choice changes the blast-radius story entirely.